Reprezentácia textovej informácie
Keď chceme pracovať s textovou informáciu v počítači musíme ju najprv nejakým spôsobom vedieť v počítači reprezentovať. Veľmi výhodnou možnosťou je rozložiť textovú informáciu na jednotlivé znaky.
Znakom nie sú len malé a veľké písmená, ale aj číslice, špeciálne znaky – čiarka, bodka, plus, pomlčka, dvojbodka, matematické operácie plus, minus aj takzvané neviditeľné znaky. To sú napríklad medzera, tabulátor, koniec riadku, koniec súboru a iné.
Keď máme text rozložený na jednotlivé znaky, zistíme, že týchto znakov nie je nejako veľa. Sú len rôzne usporiadané a tým vytvárajú text. Teraz každému znaku priradíme nejaký kód a následne v súbore celý text zapíšeme ako postupnosť kódov znakov textu.
Takéto priradenie kódov znakom nazývame kódová tabuľka.
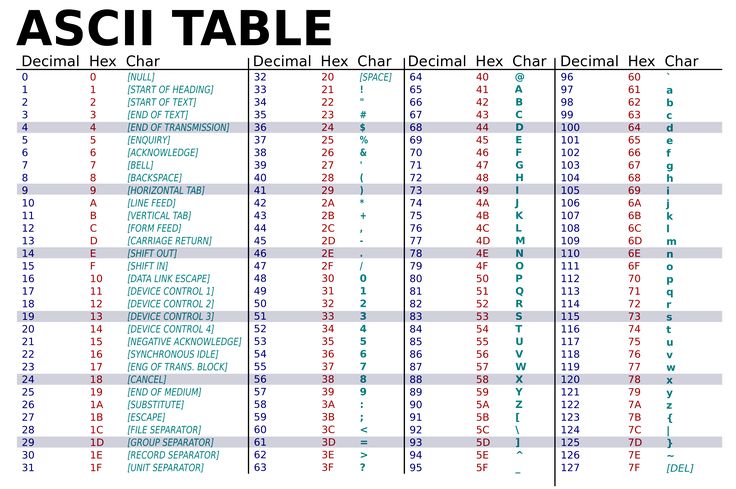
V minulosti boli znaky kódované pomocou 7 bitov. To umožnilo kódovať 128 znakov.
Takéto kódovanie označujeme ASCII.
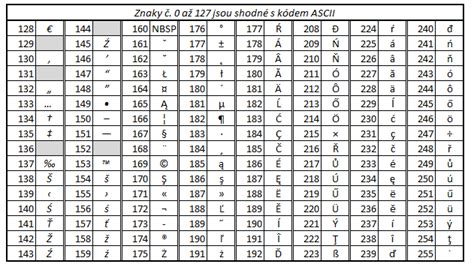
Toto kódovanie celkom stačilo pre anglickú abecedu a množinu základných symbolov. Ale aj ostatné národy chcú písať svoje texty cez diakritiku a preto sa začalo používať na kód znaku 8 bitov = 1 byte. Teda dalo sa zapísať 256 rôznych znakov. Prvých 128 znakov bolo spoločných, zodpovedali pôvodnému ASCII kódovaniu. Zvyšných 128 znakov si každé kódovanie vybralo podľa svojich potrieb. Vznikla rozšírená ASCII tabuľka.
Spočiatku bol takýto systém výhodný. Umožňoval písať texty v národných abecedách s diakritikou. Ale neskôr s rozvojom počítačových sietí dochádzalo čoraz častejšie k problémom. Každé kódovanie malo znaky s kódmi 129 až 255 rôzne. To spôsobilo, že ak sme napísali text v programe s nastaveným kódovaním napríklad pre strednú Európu a poslali sme ho niekomu, kto používal kódovanie pre západnú Európu, tak znaky anglickej abecedy sa zobrazili korektne, ale znaky s diakritikou a rôzne špeciálne znaky sa mohli zobraziť úplne nezmyselne.
Pre Strednú Európu vzniklo viacero kódovaní: windows-1250, ISO-8859-2, MacCE, IBM-852 a pod.